









'까벨로퍼 > movemove' 카테고리의 다른 글
| movemove 앱 을 소개합니다. (0) | 2024.05.15 |
|---|---|
| movemove 사용설명서 (0) | 2024.05.14 |

 2024.05.16
2024.05.16
| movemove 앱 을 소개합니다. (0) | 2024.05.15 |
|---|---|
| movemove 사용설명서 (0) | 2024.05.14 |

movemove (#무브무브) 앱은 단체 군무, 댄스, 뮤지컬 및 여러 사람이 함께 무대에서 공연하는 모든 활동에 최적화된 혁신적인 도구입니다. 이 앱을 사용하면 공연 준비 과정에서 가장 중요하면서도 복잡한 부분인 대형 구성과 동선 디자인을 손쉽게 할 수 있습니다.
프로젝트를 시작할 때, 사용자는 공연에 참여하는 멤버들을 추가할 수 있습니다. 각 멤버는 고유한 아이콘으로 표시되며, 이를 무대 위에 자유롭게 배치할 수 있습니다. 멤버의 수나 위치를 변경하는 것도 간단한 드래그 앤 드롭으로 가능합니다.
공연의 시간적 흐름에 따른 동선 변화를 구현하기 위해, movemove 앱에서는 '페이즈'라는 개념을 도입했습니다. 각 페이즈는 공연의 한 장면 또는 한 부분을 나타내며, 사용자는 페이즈마다 멤버들의 위치를 개별적으로 조정할 수 있습니다. 이를 통해 복잡한 군무나 대형 변화도 쉽게 구성할 수 있습니다.
음악은 공연에서 빼놓을 수 없는 요소입니다. movemove 앱에서는 음악 파일을 직접 로드하여 프로젝트에 연결할 수 있습니다. 음악이 재생되는 동안, 설정한 동선에 따라 멤버들의 아이콘이 자동으로 움직입니다. 이를 통해 실제 공연을 하기 전에 전체 쇼를 미리 시뮬레이션 해볼 수 있습니다.
프로젝트를 저장하고 불러오는 것도 쉽습니다. 모든 프로젝트는 로컬에 안전하게 저장되므로, 언제든지 이전 작업을 이어갈 수 있습니다. 또한, 완성된 프로젝트를 다른 사람과 공유하여 협업할 수도 있습니다.
movemove 앱의 직관적이고 사용자 친화적인 인터페이스는 누구나 쉽게 배우고 사용할 수 있도록 설계되었습니다. 이 앱을 사용하면 공연 준비에 드는 시간과 노력을 대폭 줄일 수 있습니다. 또한, 아이디어를 시각화하고 실험해볼 수 있어 더 창의적이고 완성도 높은 공연을 만들어낼 수 있습니다.
군무, 댄스, 뮤지컬 등 다양한 장르의 공연에 참여하는 모든 사람에게 movemove 앱은 필수적인 도구가 될 것입니다. 지금 바로 movemove를 다운로드하고, 더 쉽고 효율적인 방법으로 공연을 준비해보세요.
아래 링크를 클릭하여 앱을 다운로드 받을 수 있습니다.
https://play.google.com/store/apps/details?id=com.ccassak.movemove&hl=ko&gl=US
movemove #무브무브 #뭅뭅 #안무동선 #대형짜기 - Google Play 앱
단체 군무, 댄스, 무대 활동을 위한 직관적인 동선 디자인 및 구성 앱 #무브무브 #뭅뭅 #안무동선 #대형짜기 #동선짜기 #movmov
play.google.com
| [movemove] App User Manual (0) | 2024.05.16 |
|---|---|
| movemove 사용설명서 (0) | 2024.05.14 |
movemove 앱은 단체 군무, 댄스 및 여러 사람이 무대를 사용하는 활동에 최적화된 도구입니다.
앱을 통해 사용자는 손쉽게 대형을 구성하고, 멤버들의 동선을 디자인하고 음악과 함께 전체 쇼를 감상할 수 있습니다.
완성된 프로젝트는 언제든지 불러와 수정 및 재사용할 수 있습니다.
movemove 앱은 직관적인 인터페이스와 강력한 기능으로 단체 공연 준비 과정을 획기적으로 간소화합니다.











| [movemove] App User Manual (0) | 2024.05.16 |
|---|---|
| movemove 앱 을 소개합니다. (0) | 2024.05.15 |
1>***.obj : error LNK2001: 확인할 수 없는 외부 기호 _vsnprintf_s
1>***.obj : error LNK2001: 확인할 수 없는 외부 기호 sscanf_s
위와 같은 에러를 만났다면, 아래와 같이 처리 해보시기 바랍니다.
기존 낮은버전의 VisualStudio 에서 생성한 프로젝트를 높은 버전의 VisualStudio 에서 열어서 컴파일할때,
ex) vc2010 또는 vc2015 에서 생성한 프로젝트를 vc2022 에서 열어서 빌드할경우 위와 같은 에러 메세지를 출력
프로젝트 속성 페이지를 열어 링커 > 입력 > 추가종속성에
legacy_stdio_definitions.lib 를 추가

1>"zwnmsd.vcxproj" 프로젝트를 빌드했습니다.
========== 모두 다시 빌드: 1 성공, 0 실패, 0 건너뛰기 ==========
========== 다시 빌드이(가) 오전 10:52에 완료되었으며, 17.992 초이(가) 걸림 ==========
정상적으로 컴파일이 되는 것을 확인.
| 만든 앱을 앱스토어 뱃지 아이콘을 이용해 앱 링크걸기 (0) | 2023.08.31 |
|---|---|
| 만든 앱을 구글 뱃지 아이콘을 이용해 앱 링크걸기 (0) | 2023.08.30 |
| HexCode - 투명도 대응 (0) | 2022.09.28 |
| [Linux] 일별 파일백업 tar + gz + crontab (0) | 2022.06.22 |
| 개인정보처리방침 (0) | 2022.06.08 |
import datetime
import os
class Data:
oid = ''
line = ''
oidnum = []
def snmp_oid_compare(in_name1, len1, in_name2, len2):
name1 = in_name1
name2 = in_name2
# len = minimum of len1 and len2
len_val = min(len1, len2)
# find first non-matching OID
for _ in range(len_val):
if name1[0] != name2[0]:
return -1 if name1[0] < name2[0] else 1
name1 = name1[1:]
name2 = name2[1:]
# both OIDs equal up to length of shorter OID
if len1 < len2:
return -1
elif len2 < len1:
return 1
else:
return 0
dir_dump = "./dumps"
def load_dumpfile(lst):
if not os.path.isdir(dir_dump):
print("\n dir [./dumps] not found. exit.")
exit(0)
filelist = os.listdir(dir_dump)
for li in filelist:
fullpath = dir_dump + "/" + li
f = open(fullpath, 'r')
lines = f.readlines()
i = 0
for line in lines:
i += 1
if 'No Such Object' in line or line[0] != '.':
print("[skip] not start dot(.) or failed oid: {}".format(line))
continue
tokens = line.split("=")
data = Data()
data.oid = tokens[0].rstrip()
data.line = line
data.oidnum = list(map(int, filter(None, data.oid.split("."))))
lst.append(data)
f.close()
def quicksort_oid(lst):
if len(lst) <= 1:
return lst
else:
pivot = lst[len(lst) // 2]
less = [x for x in lst if snmp_oid_compare(x.oidnum, len(x.oidnum), pivot.oidnum, len(pivot.oidnum)) < 0]
equal = [x for x in lst if snmp_oid_compare(x.oidnum, len(x.oidnum), pivot.oidnum, len(pivot.oidnum)) == 0]
greater = [x for x in lst if snmp_oid_compare(x.oidnum, len(x.oidnum), pivot.oidnum, len(pivot.oidnum)) > 0]
return quicksort_oid(less) + equal + quicksort_oid(greater)
def main():
my_list = []
t1 = datetime.datetime.now()
load_dumpfile(my_list)
t2 = datetime.datetime.now()
print('\nDuration load_dumpfile: {}'.format(t2 - t1))
sorted_list = quicksort_oid(my_list)
t3 = datetime.datetime.now()
print('\nDuration quicksort_oid: {}'.format(t3 - t2))
print("\n")
i = 0
file_path = "output.txt"
with open(file_path, "w") as file:
for item in sorted_list:
i += 1
file.write(f"{item.line}")
print('Total process lines : {}'.format(i))
if __name__ == "__main__":
start_time = datetime.datetime.now()
main()
end_time = datetime.datetime.now()
print('Duration: {}'.format(end_time - start_time))| [python] snmp oid 정렬 프로그램 (0) | 2023.12.13 |
|---|---|
| [python] oid sort (0) | 2023.03.13 |
| [python] json 에서 특정 키가 존재하는지 (0) | 2022.06.09 |
요구 : 디렉토리내 모든 snmp dump 파일을 읽어서 oid 별로 정렬하여 하나의 파일로 생성
import datetime
import os
class Data:
oid = ''
line = ''
def snmp_oid_compare(in_name1, len1, in_name2, len2):
name1 = in_name1
name2 = in_name2
# len = minimum of len1 and len2
len_val = min(len1, len2)
# find first non-matching OID
for _ in range(len_val):
if name1[0] != name2[0]:
return -1 if name1[0] < name2[0] else 1
name1 = name1[1:]
name2 = name2[1:]
# both OIDs equal up to length of shorter OID
if len1 < len2:
return -1
elif len2 < len1:
return 1
else:
return 0
dir_dump = "./dumps"
def main():
my_list = []
if not os.path.isdir(dir_dump):
print("\n dir [./dumps] not found. exit.")
exit(0)
filelist = os.listdir(dir_dump)
for li in filelist:
fullpath = dir_dump + "/" + li
f = open(fullpath, 'r')
lines = f.readlines()
i = 0
for line in lines:
i += 1
if 'No Such Object' in line or line[0] != '.':
print("[skip] not start dot(.) or failed oid: {}".format(line))
continue
tokens = line.split("=")
data = Data()
data.oid = tokens[0].rstrip()
data.line = line
new_oid = list(map(int, filter(None, data.oid.split("."))))
found = False
for j, item in enumerate(my_list):
stored_oid = list(map(int, filter(None, item.oid.split("."))))
result = snmp_oid_compare( stored_oid, len(stored_oid), new_oid, len(new_oid))
if result >= 0:
my_list.insert(j, data)
found = True
print("정렬 line:%s,idx:%s,new:%s,old:%s" % (i, j, data.oid, item.oid))
break
if not found:
my_list.append(data)
f.close()
print("\n")
i = 0
file_path = "output.txt"
with open(file_path, "w") as file:
for item in my_list:
i += 1
file.write(f"{item.line}")
print('Total process lines : {}'.format(i))
if __name__ == "__main__":
start_time = datetime.datetime.now()
main()
end_time = datetime.datetime.now()
print('Duration: {}'.format(end_time - start_time))
| [python] quick sort 를 사용한 snmp oid 정렬 예제 (0) | 2023.12.13 |
|---|---|
| [python] oid sort (0) | 2023.03.13 |
| [python] json 에서 특정 키가 존재하는지 (0) | 2022.06.09 |
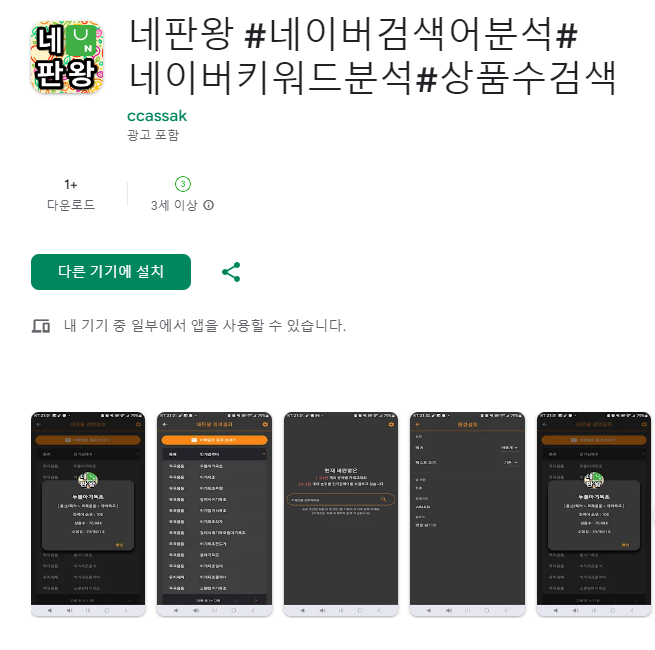
네판왕 안드로이드용 앱이 출시가 되었습니다. IOS는 심사중입니다.
구글 플레이 스토어에서 '네판왕' 으로 검색하시면 다운로드 받을 수 있습니다.
앱에서 따로 권한을 요구하는 건 없습니다.
관심 있으신 분들은 다운 받으셔서 이용 해 보시면 감사하겠습니다.
네이버 쇼핑 검색어 트랜드에 인기검색어 순위를 토대로 네이버 쇼핑에서 상품수를 분석하여 결과를 제공합니다.
* 검색어(keyword)는 &(and) 조건과 , (or) 로 두개의 단어를 조합하여 검색할 수 있습니다.
* 검색된 결과 내에서 전체상품수에서 해당 키워드로 존재하는 상품수 비율 정보를 표시합니다.
* 결과를 csv 형태로 이메일로 전송 할 수 있습니다.
* 현재 검색 결과는 최대 300건으로 제한되어 있습니다. (변경예정)
| [네판왕] 네이버 쇼핑 검색어 트랜드를 통한 상품수 검색량 리뉴얼 (0) | 2023.09.10 |
|---|---|
| [네판왕] 네이버 광고 키워드 검색량 프로그램 (무료배포) (0) | 2021.06.01 |
| [네판왕] 네이버 광고 키워드 검색량 무료 프로그램 업데이트 (0) | 2021.01.16 |
| [네판왕] 네이버 광고 키워드 검색량 무료 프로그램 재소개 (0) | 2020.08.01 |
| 네판왕 설치하기(네이버 광고 키워드 상품수 검색 프로그램) (0) | 2020.07.12 |
시작하기에 앞서
네이버의 광고키워드가 많이 바껴서 기존 프로그램이 동작하지 않는 것을 확인했습니다.
웹 스터디도 계속 할겸 일단 웹버전으로 간단히 만들고 추후에 앱버전으로 만들 생각에 개발을 진행 했습니다.
이제는 키워드 검색으로 연관된 몯든 키워드의 조회수를 뽑는게 쉽지는 않는 것 같습니다.
그래서, 네이버 데이터랩의 쇼핑인사이트의 분야별 인기검색어를 1~100위 까지 수집하도록 하였습니다.
그리고 수집된 각 인기검색어를 대상으로 네이버 쇼핑몰의 전체 상품수를 수집하여 보여주도록 하였습니다.
이 데이타가 유용하게 쓰이시는 분들도 계실거라 생각합니다.
좀더 어떻게 하면 더 좋은 정보나 기능을 제공할지는 차차 고민해서 개선 하도록 할 생각입니다.

VoLab
volab.kr
| [네판왕] 앱버전이 출시되었습니다. (0) | 2023.10.11 |
|---|---|
| [네판왕] 네이버 광고 키워드 검색량 프로그램 (무료배포) (0) | 2021.06.01 |
| [네판왕] 네이버 광고 키워드 검색량 무료 프로그램 업데이트 (0) | 2021.01.16 |
| [네판왕] 네이버 광고 키워드 검색량 무료 프로그램 재소개 (0) | 2020.08.01 |
| 네판왕 설치하기(네이버 광고 키워드 상품수 검색 프로그램) (0) | 2020.07.12 |
거의 방치하시다피한 volab.kr 사이트를 다시 여러 스터디 목적으로 정리 해볼까 하고 서버를 다시 구축했습니다.
기존에 centos7 에서 Rocky Linux 9 x64 로 변경했습니다.

사용료가 한달에 5$ 정도 됩니다. 관심 있으시면 아래 추천링크로
SSD VPS Servers, Cloud Servers and Cloud Hosting
Vultr Global Cloud Hosting - Brilliantly Fast SSD VPS Cloud Servers. 100% KVM Virtualization
www.vultr.com
홈페이지는 아래와 같이 생겼습니다.
UI에 대한 미적감각이 전무하기 때문에..

주제는 이것저것 필요에 의해서나 공부겸 해서 하나씩 추가할 예정인데,
우선 1. SNMP MIB Finder라고 snmp mib vendor 를 검색하는 사이트를 만들어봤고,
2. NIC 제조사를 찾는 사이트도 만들어 봤습니다. OUI 를 통해서 제조사를 구분 지울 수 있습니다.
3. Auto ETrade Hist 라고 이베스트 투자증권에서 제공하는 Xing API 를 가지고 실제 투자를 하고 있는데,
매번 앱을 열어서 확인 하기 힘들어서 웹에 거래 이력을 표시하는 사이트를 만들어 봤습니다. 나름 자동매매인데 그닥 수익률은 좋지 않습니다.. 스터디!
4. 전 세계 살사 행사들에 대한 스케줄 정보를 제공하는 사이트 입니다. 앱 버전으로도 이용 할 수 있습니다.
5. 국내 살사 파티 이벤트에 대한 정보를 제공하는 사이트 입니다. 마찬가지로 앱버전으로도 이용 할 수 있습니다. (4번과 동일앱)
그리고 앞으로도 관심있는거에 대해 하나씩 추가할 예정입니다.
| volab.kr - 추가기능 IPO 공모 현황 (0) | 2021.06.30 |
|---|---|
| VoLab.kr 을 소개합니다. (0) | 2021.06.26 |
1. 아래 링크에서 자신의 앱을 검색
https://tools.applemediaservices.com/app-store/
Market with App Store
Easily create custom marketing assets to share your app on social media or web banners. Simply search for your app, choose a template, customize your design, and add preset messages in multiple languages. Learn more
tools.applemediaservices.com

2. 앱을 클릭하여 상세 페이지로 이동

3. Link 주소를 복사하여 사용해도 되고 이미지를 직접 다운 로드 받아서 작업 해도 된다.
| error LNK2001: 확인할 수 없는 외부 기호 _vsnprintf_s1 error LNK2001: 확인할 수 없는 외부 기호 sscanf_s 에러 발생시 (0) | 2024.03.20 |
|---|---|
| 만든 앱을 구글 뱃지 아이콘을 이용해 앱 링크걸기 (0) | 2023.08.30 |
| HexCode - 투명도 대응 (0) | 2022.09.28 |
| [Linux] 일별 파일백업 tar + gz + crontab (0) | 2022.06.22 |
| 개인정보처리방침 (0) | 2022.06.08 |
1. 아래 링크에서 자신의 앱을 검색
https://play.google.com/store/games?device=windows

2. 주소창에 나와있는 앱 URL 을 복사
https://play.google.com/store/apps/details?id=com.ccassak.wsf
3. 구글 플레이 뱃지 이미지 얻기
아래의 URL 로 접속
https://play.google.com/intl/en_us/badges/

위 화면에서 Play Store URL 인풋창에 자신의 앱 URL 을 넣으면, 왼쪽 HTML 링크가 생성됨
이미지 소스는 url 을 토해 가져다 쓰는 것이기 때문에 사이즈가 큼
본인은 뱃지를 다운 받아서 사이즈를 작게 조절하였음.

| error LNK2001: 확인할 수 없는 외부 기호 _vsnprintf_s1 error LNK2001: 확인할 수 없는 외부 기호 sscanf_s 에러 발생시 (0) | 2024.03.20 |
|---|---|
| 만든 앱을 앱스토어 뱃지 아이콘을 이용해 앱 링크걸기 (0) | 2023.08.31 |
| HexCode - 투명도 대응 (0) | 2022.09.28 |
| [Linux] 일별 파일백업 tar + gz + crontab (0) | 2022.06.22 |
| 개인정보처리방침 (0) | 2022.06.08 |
import requests, json, urllib3, datetime, sys
import os
import re
class Line:
def __init__(self, line):
self.no=0
self.line=line
dir_dump = "./dumps"
def main():
lst = []
dic = dict()
if os.path.isdir(dir_dump) == False:
print("\n dir [./dumps] not found. exit.")
exit(0)
filelist = os.listdir(dir_dump)
for li in filelist:
fullpath = dir_dump + "/" + li
f = open(fullpath, 'r')
lines = f.readlines()
for line in lines:
if 'No Such Object' in line or line[0] != '.':
print("[skip] not start dot(.) or failed oids: {}".format(line))
continue
tokens = line.split("=")
keys = tokens[0].strip()
keys = keys[1:]
o = Line(line)
dic[keys] = o
f.close()
# list로 변환
lst = [*dic]
# oid 문자열을 숫자 기반으로 정렬
lst = sorted(lst, key=lambda y: tuple(int(x) for x in y.split('.')))
print(lst)
for index, value in enumerate(lst):
if dic.get(value) is not None:
dic[value].no = index
# 키로 정렬
sorted_dict = sorted(dic.items(), key = lambda item: item[1].no, reverse = False)
print("\n")
i = 0
wf = open("result.txt", 'w')
for li in sorted_dict:
i = i+1
wf.write(li[1].line)
wf.close()
print('Total process lines : {}'.format(i))
if __name__ == "__main__":
start_time = datetime.datetime.now()
main()
end_time = datetime.datetime.now()
print('Duration: {}'.format(end_time - start_time))
| [python] quick sort 를 사용한 snmp oid 정렬 예제 (0) | 2023.12.13 |
|---|---|
| [python] snmp oid 정렬 프로그램 (0) | 2023.12.13 |
| [python] json 에서 특정 키가 존재하는지 (0) | 2022.06.09 |
TextField(
decoration: InputDecoration(
border: OutlineInputBorder(
borderRadius: BorderRadius.circular(10.0),
),
filled: true,
hintStyle: TextStyle(color: Colors.grey[800]),
hintText: "Type in your text",
fillColor: Colors.white70),
)
| 만든 앱을 앱스토어 뱃지 아이콘을 이용해 앱 링크걸기 (0) | 2023.08.31 |
|---|---|
| 만든 앱을 구글 뱃지 아이콘을 이용해 앱 링크걸기 (0) | 2023.08.30 |
| [Linux] 일별 파일백업 tar + gz + crontab (0) | 2022.06.22 |
| 개인정보처리방침 (0) | 2022.06.08 |
| [linux] 하위 폴더 및 파일 찾아서 삭제 (0) | 2021.09.02 |
#1. 적당한 위치에 백업 폴더를 생성
#2. 스크립트 작성
$ vi backup.sh
| #!/bin/bash now=`date +%Y%m%d` dest="volab-backup-$now.tar.gz" tar cvfz /var/backup/$dest /var/www/volab/ |
#3. 스크립트 실행
$ ./backup.sh

#4. 이걸 crontab 에 등록 하여 하루에 한번 백업을 실행하도록
# crontab -l <- 작업 리스트 보기
# crontab -e <- 작업 수정
# crontab -r <- 모든 작업 삭제
$ crontab -e
5. 매일 새벽 01시에 실행
00 1 * * * /var/backup.sh
#5. 작업이 등록되어 있는지 확인
[root@vultr backup]# crontab -l
00 1 * * * /var/backup.sh
#6. 서비스 재실행
[root@vultr backup]# service crond restart
Redirecting to /bin/systemctl restart crond.service
| 만든 앱을 구글 뱃지 아이콘을 이용해 앱 링크걸기 (0) | 2023.08.30 |
|---|---|
| HexCode - 투명도 대응 (0) | 2022.09.28 |
| 개인정보처리방침 (0) | 2022.06.08 |
| [linux] 하위 폴더 및 파일 찾아서 삭제 (0) | 2021.09.02 |
| [REACT] axio / d3 / react 16 / react 17 개발 일기 (0) | 2021.08.20 |